Our practice at B&A walked into this project after five months of development. The team was defeated. Frustrated. Ready to give up. I sat through a 20-minute rant from someone insisting it was impossible-that AI simply couldn't handle the nuance required for production-grade compliance decisions.
But is that true?
They had not seen our work on it yet.
In early 2026, our engineering team faced the critical question that every enterprise AI system eventually confronts: "We know the system works in testing, but what is its reliable accuracy in production?"
The existing system had been designed to ingest software vulnerabilities (CVEs) and determine their impact on legacy infrastructure. The initial prototype demonstrated competence in reading comprehension and contextual reasoning. But relying on qualitative assessment-simply observing that the outputs "look correct"-is insufficient for production environments handling sensitive data.
We paused feature development to conduct a rigorous, scientific benchmark. We deconstructed the system to measure exactly how well current State-of-the-Art (SOTA) Large Language Models (LLMs) can interpret complex compliance data.
Phase 1: The "Prompt Gap" Discovery
We established a "Golden Dataset" consisting of 152 historical records that had been manually classified by Subject Matter Experts (SMEs). We ran these records through our production models using our standard prompt architecture.
The Initial Result
The system yielded an accuracy rate between 10% and 40% depending on the model.
The Root Cause Analysis
Upon analyzing the logs, we discovered that the models were not hallucinating; they were failing to commit. The LLMs provided nuanced, paragraph-length analysis of the risks but failed to output a binary classification ("Affected" vs. "Not Affected"). Our deterministic evaluation layer interpreted this nuance as a failure to identify the risk.
The Remediation
We adjusted the prompt to enforce a strict output schema, appending a directive to provide a "Final Determination" tag. This single architectural change raised accuracy from 40% to ~80-90% across the board.
Phase 2: The Multi-Model Benchmark (January 2026)
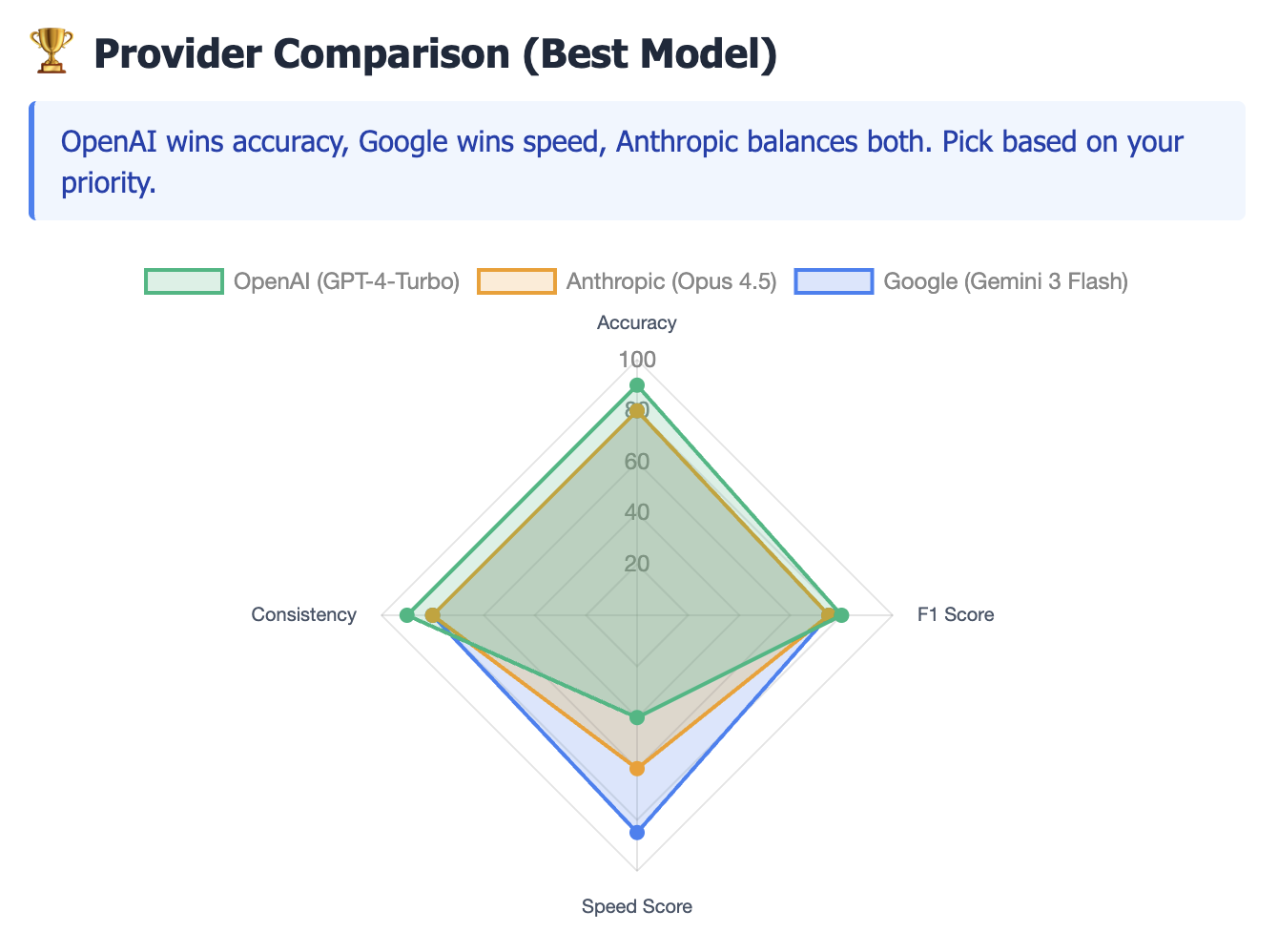
With the schema validation fixed, we executed a comparative study of 9 models across three major providers (OpenAI, Anthropic, and Google). We measured performance based on Accuracy, Latency, and F1 Score (the harmonic mean of Precision and Recall).
Note: The results below are from an initial sample of 10 records. We will publish updated metrics as we complete the full benchmark across all 152 records in the training dataset.
Performance Leaderboard
| Model | Accuracy | F1 Score | Latency |
|---|---|---|---|
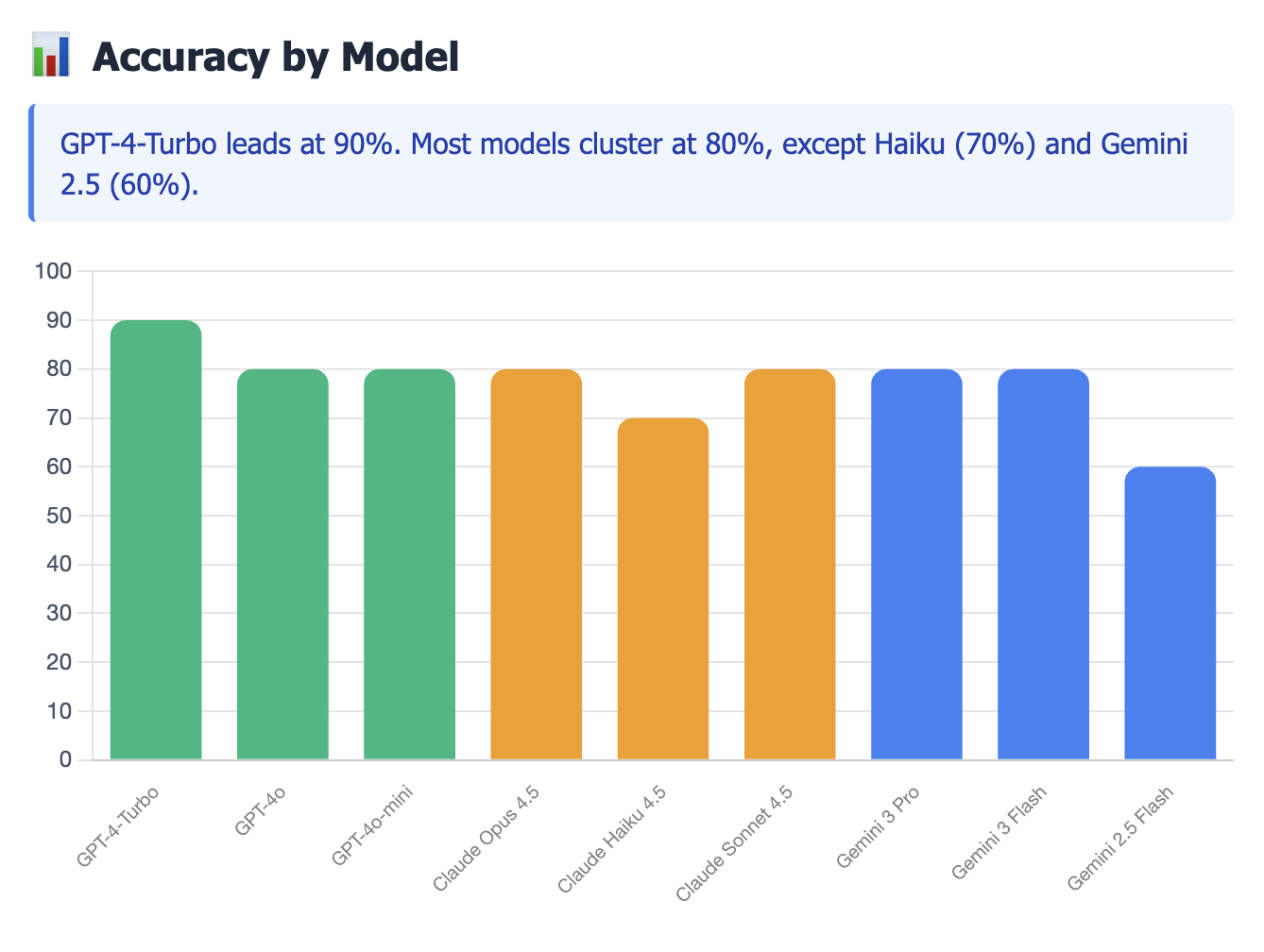
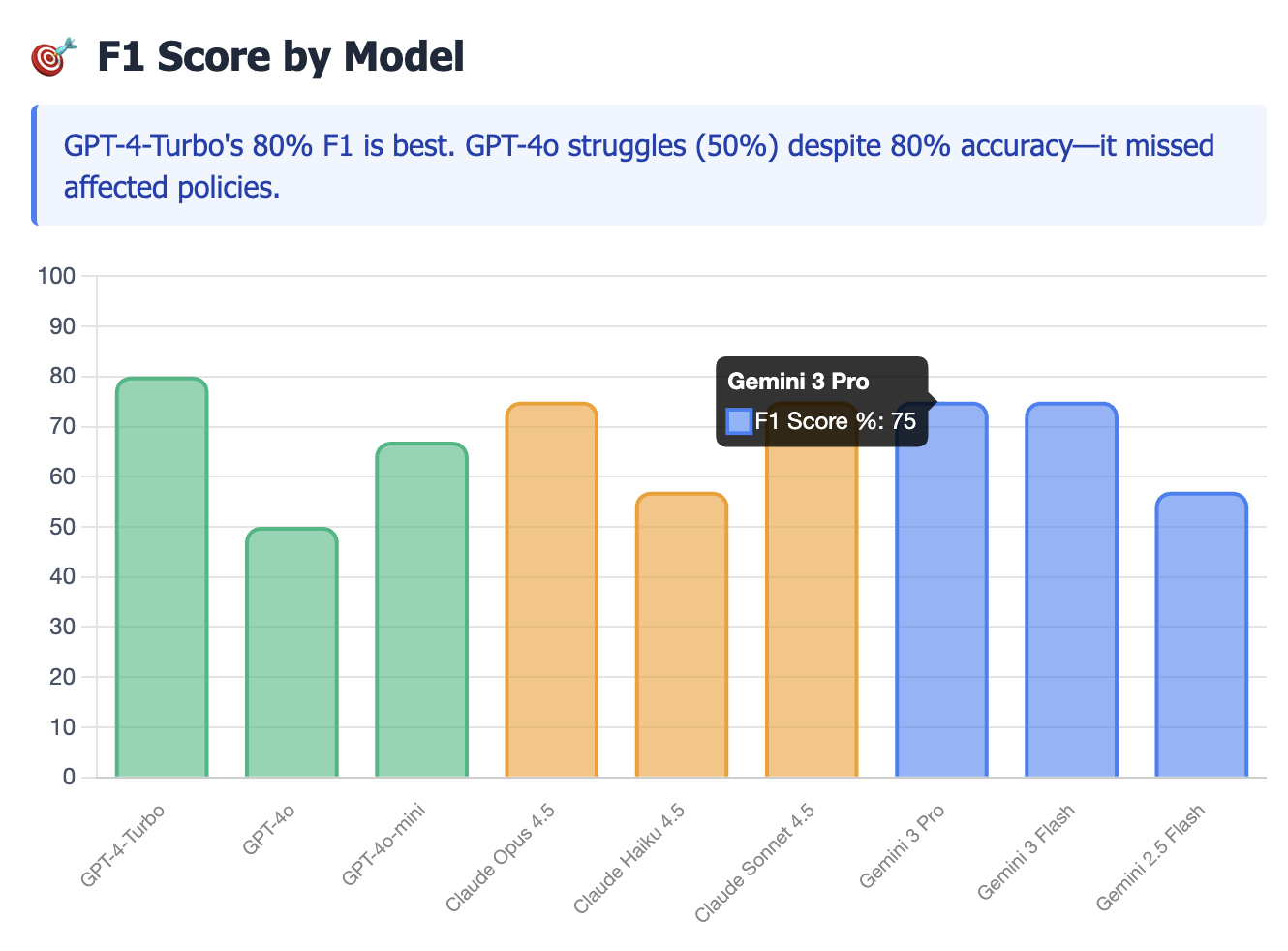
| GPT-4-Turbo | 90% | 80% | 31s |
| GPT-4o | 80% | 50% | 11s |
| Claude Opus 4.5 | 80% | 75% | 23s |
| Gemini 3 Pro | 80% | 75% | 28s |
| Gemini 2.5 Flash | 60% | 57% | 16s |
Key Technical Findings
The Precision Leader: GPT-4-Turbo was the only model to achieve 90% accuracy. Critically, it achieved 100% Precision in our sample set, meaning it produced zero false positives.
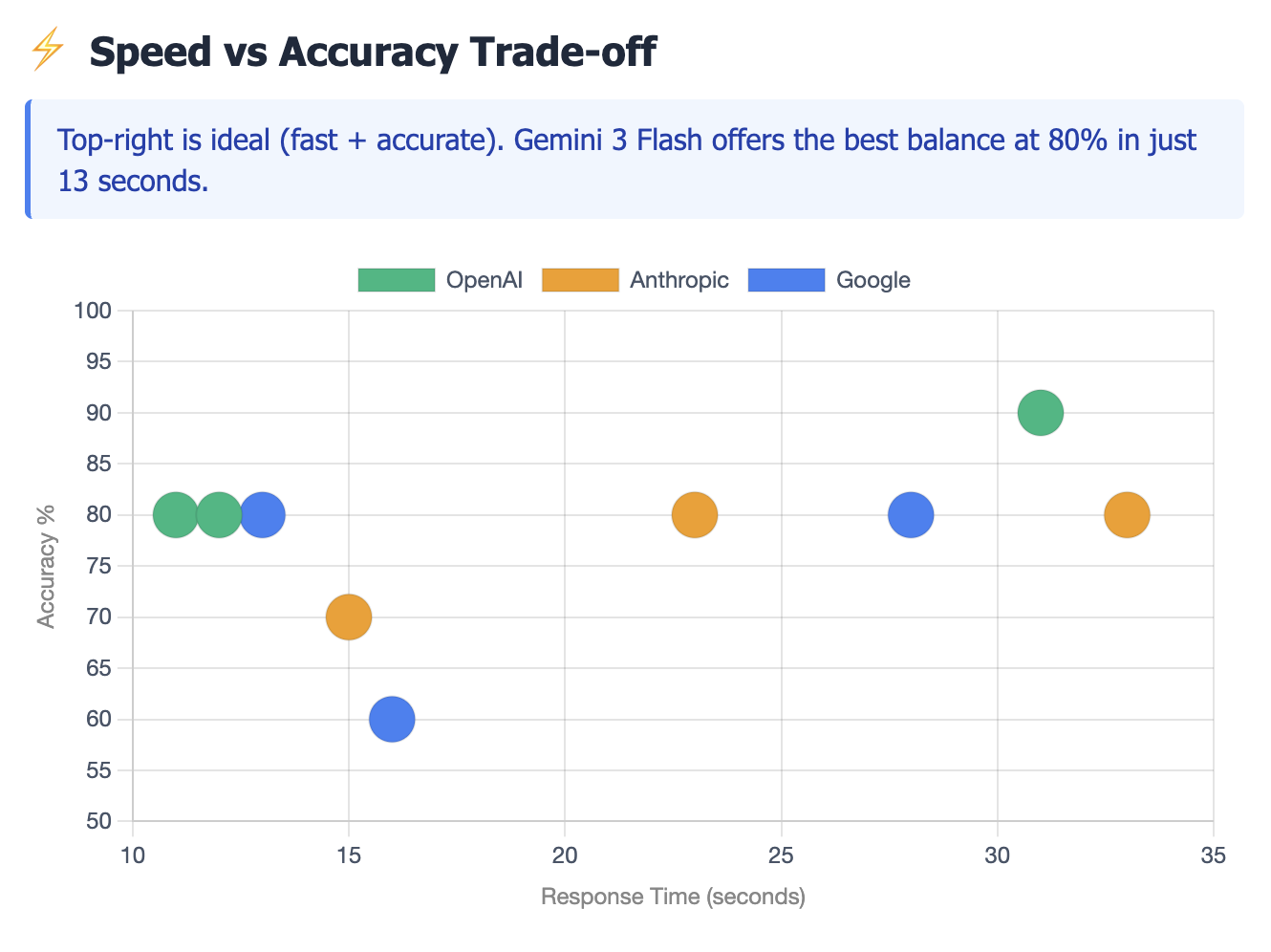
The Speed/Accuracy Trade-off: While GPT-4o offered significantly lower latency (11s avg), its F1 score dropped to 50% due to lower recall. For compliance tasks where missing a vulnerability is unacceptable, the slower, more reasoning-heavy model (Turbo) is the necessary choice.
Model Maturity Matters: The benchmark revealed significant performance degradation in older "stable" models (Gemini 2.5 Flash) compared to newer preview models.
Phase 3: The "Ambiguity Ceiling"
A distinct pattern emerged during testing: seven of the nine models hit a hard performance ceiling at 80% accuracy.
Deep-dive analysis revealed that specific records (e.g., Record ID 14170) were universally misclassified by every model, including GPT-4-Turbo. Upon review with SMEs, we determined that these edge cases contained ambiguous ground truth data-scenarios where even human experts debated the classification.
Where Do We Go From Here?
With a baseline established, the real engineering begins. Here are the creative solutions we're exploring to push past the 80% ceiling and achieve true production reliability:
1. Multi-Model Ensemble Voting
Instead of relying on a single model, we could run complex cases through multiple LLMs in parallel (GPT-4-Turbo, Claude Opus, Gemini Pro) and use a voting mechanism. If 2 of 3 models agree, we accept the classification. Disagreements get flagged for human review. This could dramatically reduce false negatives while maintaining high precision.
2. Confidence-Based Tiering
Force the LLM to output a confidence score (0-100%) alongside its classification. High-confidence predictions (>90%) get auto-processed; medium-confidence (60-90%) get a second-pass with a different prompt or model; low-confidence (<60%) get routed to human SMEs. This creates a dynamic workload distribution based on difficulty.
3. Few-Shot Learning with Golden Examples
Inject 5-10 carefully curated examples from our Golden Dataset directly into the prompt. By showing the model "here's what we classified as Affected, and why," we may unlock better reasoning on edge cases. This is particularly promising for the ambiguous records that currently stump all models.
4. Fine-Tuned Domain Models
Train a lightweight classifier on our 152+ labeled records to handle the "easy" 60% of cases. Only escalate to expensive GPT-4-Turbo calls for the complex 40%. This could cut API costs by 50%+ while maintaining accuracy on straightforward determinations.
5. RAG-Enhanced Contextual Reasoning
Build a vector database of past vulnerability assessments and their resolutions. When a new CVE comes in, retrieve the 3 most similar historical cases and inject them as context. This gives the model real-world precedent to reason from, potentially improving accuracy on novel but similar vulnerabilities.
6. Human-in-the-Loop Feedback Pipeline
Deploy the system with a continuous learning loop: every human correction gets logged and periodically used to re-evaluate prompt strategies. Over time, we build an ever-growing corpus of "hard" examples that refine our understanding of what the model struggles with-and why.
Conclusion: Engineering Reliability
We are moving away from the assumption of autonomy and toward a Deterministic Hybrid Architecture:
- Deterministic Filtering: Code-based logic handles clear-cut negatives.
- LLM Reasoning: GPT-4-Turbo is deployed specifically for complex analysis, prioritizing Precision over Speed.
- Structured Enforcement: Output schemas are rigorously enforced to bridge the gap between probabilistic reasoning and binary compliance requirements.
This transition marks the maturity of the project. We have moved from exploring what is possible with AI to engineering what is reliable for the enterprise.
By B&A AI Center of Excellence